

4.2.1 Which existing blocks (if any) can be used for this instruction?
a) SEQ is a Boolean operation returning 1/true or 0/false if the two registers are equal.
reg, mux, alu
b) LWI leads the contents of a memory allocation that is the sum of two registry values.
reg, mux, alu, memory
Figure Below
4.2.2 Which new functional blocks (if any) do we need for this instruction?
a) a mux after ALU zero for Boolean 0 or 1
b) nothing
Figure Below
4.2.3 What new signals do we need (if any) from the control unit to support this instruction?
a) need control signal to operate new mux
b) nothing
Figure Below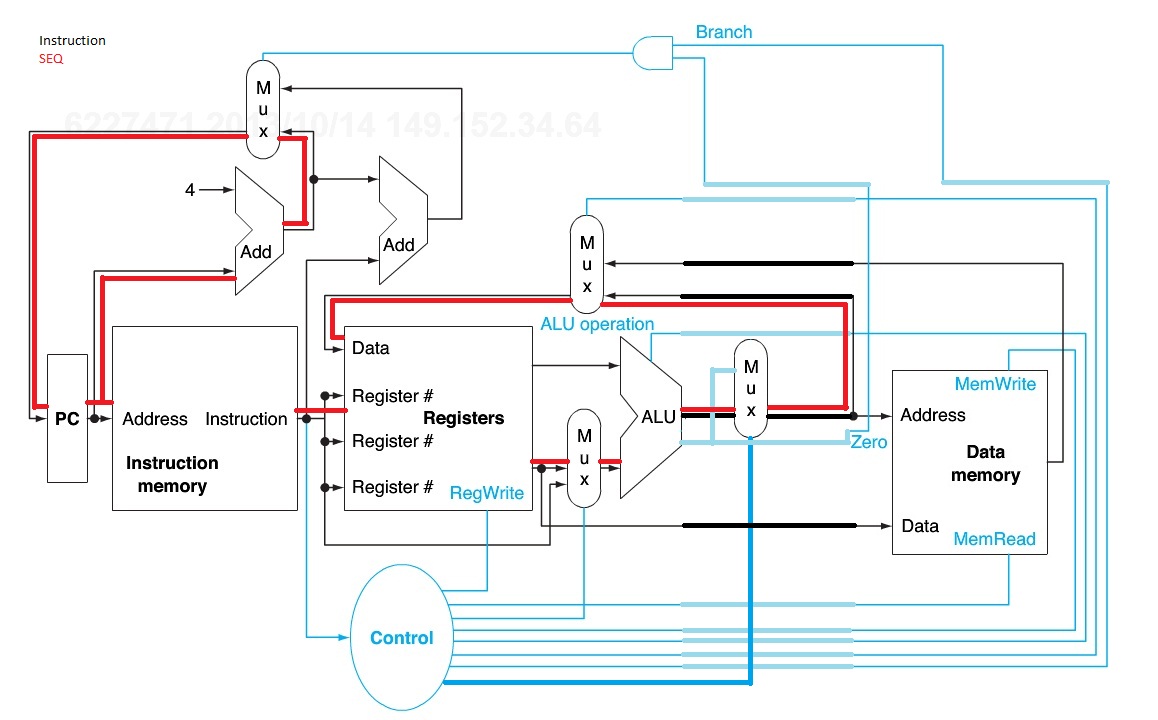

In the following three problems, assume that we are starting with a datapath from Figure
4.2, where I-Mem, Add, Mux, ALU, Regs, D-Mem, and Control blocks have latencies of 400ps, 100ps, 30ps, 120ps, 200ps, 350ps, and 100ps, respectively, and costs of 1000, 30, 10, 100, 200, 2000, and 500, respectively.
Costs
Instruction memory:1000
Registers:200
ALU:100
Data Memory:2000
Add:30*2 = 60
Mux:10*3 = 30
Control:500
Total Cost: 3890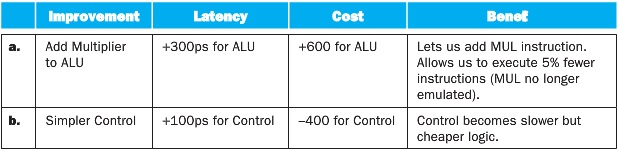
4.2.4 What is the clock cycle time with and without this improvement?
Critical Path is PC->Instruction Mem->Registers->Mux->ALU->D-Mem->Mux
400+200+30+120+350+30 = 1130ps
a. ALU latency +300: 1130+300 = 1430ps
b. Control Latency+100 - matches registers for latency, so no change in critical path - 1130ps
4.2.5 What is the speedup achieved by adding this improvement?
a.
While no direct speed up occurs in the critical path, and in fact, the
cycle time is lengthened, since it adds MUL to the instruction set, 5%
fewer instructions can be performed.
So, if we assume 1000 instructions at 1130ps, we have a run time of 1,130,000ps
Now with the improvement, we have 950 instructions at 1430 ps we have a run time of 1,358,500.
We
have a performance decrease of 225800ps, instead of an increase. The
increase in cycle time is not recovered in the decrease in instruction
count.
b. The change does not affect cycle time, therefore no speedup is achieved.
4.2.6 Compare the cost/performance ratio with and without this improvement.
I will increase the instruction count to 1million.
Cost/Performance
Cost/(1/Execution Time)
1000000*1130 = 1130000000ps
.00113sec
3890/(1/.00113)) = 4.4
a. cost 3890+600 = 4490
1000000*.95*1430 = 1358500000ps
.0013585 sec
4490/(1/.0013585) = 6.1
b. cost 3890-400 = 3490
1000000*1130 = 1130000000ps
.00113sec
3490/(1/.00113) = 3.94
Improvement
a, is not an improvement at all. The increase in cycle time is never
made up in the decrease in instruction count. When combined with the
cost of the improvement, you have a system a fair amount worse than our
baseline. To make this implementation and actual improvement, the usage
of mul will need to be used much more frequently.
Improvement
b is a true improvement. With no sacrifice to cycle time, we have a
reduced cost. Seems like an obvious improvement.
is this for mips or risc5? i am working on risc5 for comp org at utsa
ReplyDeletemips
ReplyDelete