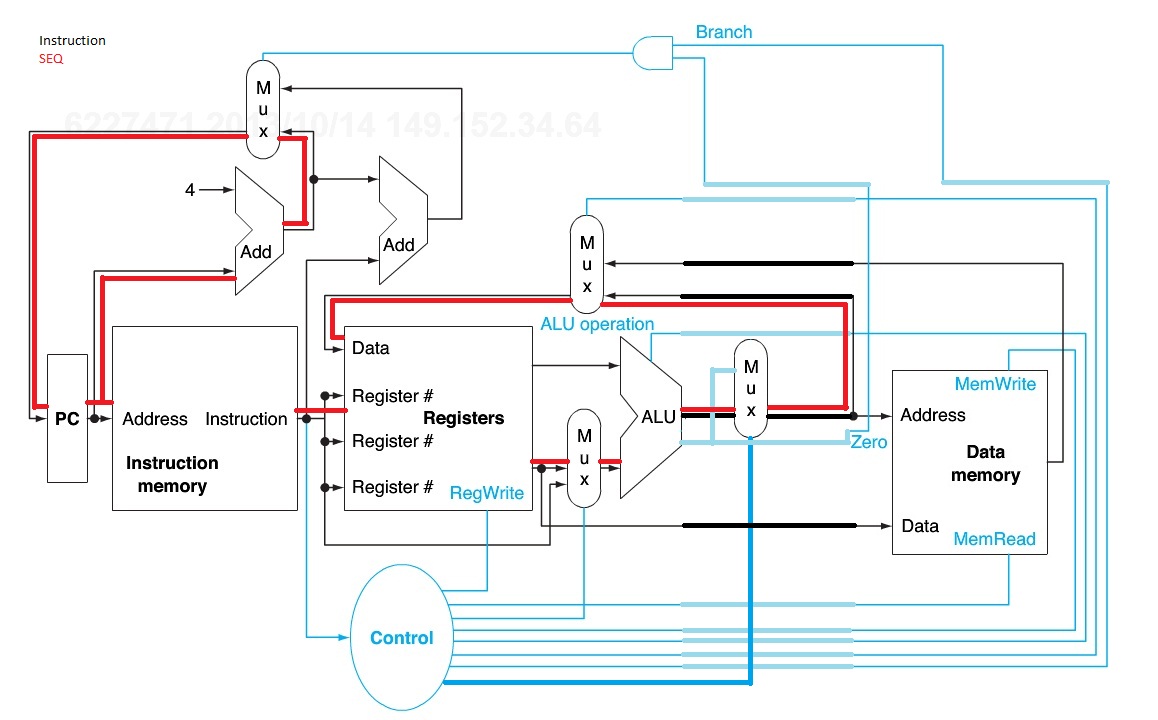
4.7.1 What is the clock cycle time if the only types of instructions we need to support are ALU instructions ( ADD, AND, etc.)? 
a) 200+90+20+90+20 = 420ps
b) 750+300+50+250+50 = 1400ps
4.7.2 What is the clock cycle time if we only have to support LW instructions? 
a) 200+90+20+90+250+20 = 670ps
b) 750+300+50+250+500+50 = 1900ps
4.7.3 What is the clock cycle time if we must support ADD, BEQ, LW, and SW instructions?
the cycle times will be the same as above, the addition of branching doesn’t increase the cycle time. Implementation a: 15+10+70+20 = 115ps which is less than data memory latencies.
Implementation b is the same: 100+5+200+20 = 350ps
For the remaining problems in this exercise, assume that there are no pipeline stalls and that the breakdown of executed instructions is as follows:
For these problems I am going to break out our chart from Open Courseware.
4.7.4 In what fraction of all cycles is the data memory used?
Data memory is used in SW and LW as we are writings and reading to memory.
a) 25+10 = 35%
b) 30+20 = 50%
4.7.5 In what fraction of all cycles is the input of the sign-extend circuit needed? What is this circuit doing in cycles in which its input is not needed?
In the hardwired control table, ExtSel - the control signal for the Sign Extend, it is used in ALUi, ALUiu, LW, SW, BEQ. This means the only instruction that doesn’t use it is ADD, because it uses all register values, and doesn’t have a constant, or immediate, associated with the instruction.
a) 20%
b) 30%
A control signal is sent to the resource to activate its use or not, however, in the figure associated with these problems, that control signal does not exist, so we must assume the function performs no matter what. However, in the case where it is not needed, even in its operations are performed, it is simply ignored because it isn’t used.
4.7.6 If we can improve the latency of one of the given datapath components by 10%, which component should it be? What is the speedup from this improvement?
There are two prime contenders here. The first is Instruction memory, since it is used every cycle. The second is Data Memory, since it has the longest latency.
We will assume 100 instructions
a)
I-Mem - 200ps - 100%
D-Mem - 250ps - 35%
200*.9 = 180 * 100 = 18000
250*.9 = 225 * 35 = 7875
200*100 = 20000 - 18000 = 2000ps change
250*35 = 8750 - 7875 = 875ps change
For a, the component to improve would be the Instruction memory.
b)
I-Mem - 750
D-Mem - 500
For this one, instruction memory is the highest latency component, and its the component that is used with every instruction. Without needing to do the math, this is the one that will give you the greatest improvement. However, here is the math anyway:
750*.9 = 675 * 100 = 67500
750-100 = 75000 - 67500 = 7500ps