Exercise 4.1
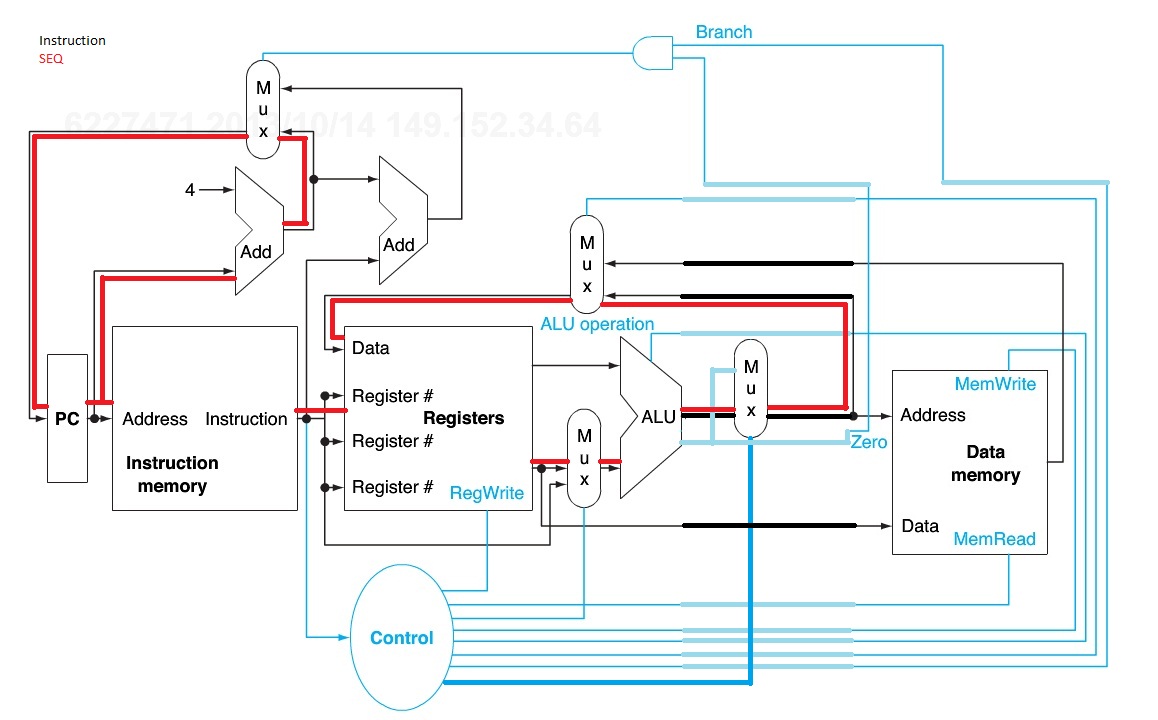
Different instructions utilize different hardware blocks in the basic single-cycle implementation. The next three problems in this exercise refer to the following instruction:
Instruction Interpretation
a. AND Rd,Rs,Rt
|
Reg[Rd] = Reg[Rs] AND Reg[Rt]
|
b. SW Rt,Offs(Rs)
|
Mem[Reg[Rs] + Offs] = Reg[Rt]
|
Figure 4.2

ExtSel is extend sign, which is not represented in our figure.
BSrc is the southern mux in the figure and is used to determine if an immediate operand or a register is passed to the ALU.
OpSel is ALU command
WBSel is middle mux, selecting whether the ALU output or a memory output is used as data.
4.1.1 What are the values of control signals generated by the control in Figure 4.2 for this instruction?
For these answers, i will be referencing the Control table above provided by MIT Open Courseware.
a) AND is an ALU Operation, so:
BSrc will look to register
OpSel will tell ALU to AND
MemW is false, we do not touch memory
RegW is true, we are writing back to register Rd
WBSrc is will set to use output from ALU as data
RegDst is Rd
PCSrc is PC + 4 since no jumps occur
b) SW is directly represented in our chart
BSrc will look to immediate operand Offs
OpSel will tell ALU to ADD the Offset to the Rs register
MemW is true, we are writing a register to memory
RegW is false, we are not writing back to a register
WBSrc is ignored
RegDst is ignored
PCSrc is PC + 4 since no jumps occur
4.1.2 Which resources (blocks) perform a useful function for this instruction?
a) pc, instruct mem, alu, mux, registers
We are not using memory or jumping
b) pc, instruct mem, alu, mux, mem, reg
4.1.3 Which resources (blocks) produce outputs, but their outputs are not used for this instruction? Which resources produce no outputs for this instruction?
a) branch, data memory
b) branch
Different execution units and blocks of digital logic have different latencies (time needed to do their work). In Figure 4.2 there are seven kinds of major blocks. Latencies of blocks along the critical (longest-latency) path for an instruction determine the minimum latency of that instruction. For the remaining three problems in this exercise, assume the following resource latencies:
Since no mention is made as to analog or digital mux, I am assuming digital and that 20ps will always be spent.
I-Mem
|
Add
|
Mux
|
ALU
|
Regs
|
D-Mem
|
Control
|
a. 200ps
|
70ps
|
20ps
|
90ps
|
90ps
|
250ps
|
40ps
|
b. 750ps
|
200ps
|
50ps
|
250ps
|
300ps
|
500ps
|
300ps
|

4.1.4 What is the critical path for an MIPS AND instruction?
Figure above outlines latencies, and calculates Critical path to ALU completion.
The PC +4 and Control have lower latencies than other parts functioning in parallel. Control is slower the the registers, and data mem is not used.
a)instruction mem, reg, mux, alu, mux
400 + 20(writeback to reg mux) = 420ps
b) 1350+20=1370ps
4.1.5 What is the critical path for an MIPS load (LD) instruction?
Load will read from mem and write to register so we must use data memory and the mux to register data.
a)400+250+20 = 670ps
b)1350+500+50 = 1900ps
4.1.6 What is the critical path for an MIPS BEQ instruction?
beq will go up to the branch, and mux the new address from the ALU output to be the new Program Counter.
a)400+20 = 420ps
b)1350+50 = 1400ps
This Exercise focus’ on Critical Paths of Operations and the resources they use.
As such, we cover 4 distinct Control variations as described in the MIT Open Courseware Figures: ALU, SW, LW, BEQ.
The resource configuration is slightly different from the one in the figure used above, however the operations performed are identical.
The Assembly I am executing is in the lower right of the images and the current register values is in the middle right.